This project examines the predictive capabilities of the ARIMA model for time series analysis. To explore the capabilities of the statsmodels library, the Python programming language will be used with jupyter notebook being the runtime environment. Along with the prediction analysis, there will be a demonstration of data retrieval using the yahoo web api, time series transformation, manual and automatic stationarity checks, benchmarking the model versus a naive benchmark, multiple days prediction and multiple symbol prediction mean error checks. The Python code in this project can be used to create a reusable module for predicting any combination of symbols with given date ranges.
Prerequisites
NEEDED BACKGROUND
The reader must be able to understand econometrics processes and be able to read Python source code. The Python ecosystem offers a great set of tools for scientific computing the libraries can be installed with the pip package management tool. The basic library I will use for this experiment is the statsmodels, a very powerful statistics library offering many statistics functions http://statsmodels.sourceforge.net/devel/index.html#table-of-contents . THE ARIMA MODEL In econometrics and time series analysis the ARIMA model, an acronym for AutoRegressive Integrated Moving Average, is a model that allows us to better understand the time series data and also predict points in the future. The model is represented as ARIMA(p, d, q) when p, d, q are non negative integers and they represent the number of passes on each individual process of the model.
p: corresponds to the “AR” part of the model. An AR(1) is called a first-order auto-regressive model for Y and it defines simple regression with an independent variable being a lagged value of Y(ex Y+1).
d: corresponds to the “I” part of the model. An I(1) is called a first-order integrated model and it defines the number of the differentiations of the time series in order to make them stationary. We define stationary series as the series whose mean, variance and autocorrelation are constant over time. Stationary series are easier to predict and stationarity can be approximated by differentiating the data points.
q: corresponds to the “MA” part of the model. An MA(1) is called a first-order moving average model and it defined the lagged forecast errors of the prediction equation.
DIAGNOSTICS
STATIONARITY
We can test a time series for stationarity using the “Augmented Dickey - Fuller” test. This is a test which executes a null hypothesis testing that there is a unit-root with the alternative hypothesis that there is no unit root. A unit root is a random trend in time series and it adds a negative effect on any attempt of prediction. If the p-value of the ad-fuller test is above a critical limit then we cannot reject the null hypothesis and the presence of a unit root. Statsmodels offers a function to perform the ad-fuller test on a time series which will be used in this experiment.
DURBIN WATSON TEST
The Durbin-Watsos test is a test statistic which reports the presence of autocorrelation in the time series. As autocorrelation we define the error of a period, transferred to another period. For example the underestimation of some profit for period A causes an underestimation of a profit for period B. This test can returns a value between 0 and 4 with 2 being no autocorrelation and the rest of the values defining the presence of positive autocorrelation (0<2) and negative autocorrelation (2<4).
Code Implementation
In order to showcase this process as good as possible, I will describe the code statements in a procedural way.
Needed modules import
The following statements load all the needed libraries for the execution of the statements. Note the rcParams dictionary. This is a way to customize how the matplotlib plots will be rendered.
%matplotlib inline
import os.path
import datetime
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pandas_datareader.data as web
import statsmodels.api as sm
import statsmodels.tsa.api as smt
from statsmodels.tsa.arima_model import ARIMA, ARIMAResults
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 15, 6
plt.style.use('ggplot')
Declaring the data space
This is the data we will use to train and test the model. Note that the given date range is not going to work for all stock symbols. The user needs to be aware of the date a specific symbol started to trade otherwise the model will throw errors about missing data.
symbol = 'MSFT'
source = 'yahoo'
start_date = '2008-01-04'
end_date = '2017-04-06'
predict_days = 2
filename = '{}_{}_to_{}.csv'.format(symbol, start_date, end_date)
Retrieving the data
To retrieve the data I am using the pandas datareader. Remember the “source” variable from the input declaration step? This is the actual service from where the data will be fetched. On the first run the data are fethced from the remote service and they are stored on a given filename using the csv file format. If you re-run this step the data will be loaded from the saved file. To achieve a naming consistency the filename consists of the symbol name and the date range as declared on the input declaration step.
start = datetime.datetime.strptime(start_date, "%Y-%m-%d")
end = datetime.datetime.strptime(end_date, "%Y-%m-%d")
if os.path.isfile(filename):
data = pd.read_csv(filename, parse_dates=True, index_col=0)
else:
data = web.DataReader(symbol, source, start, end)
data.to_csv(filename)
data.tail(5)
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2017-03-31 | 65.650002 | 66.190002 | 65.449997 | 65.860001 | 21001100 | 65.860001 |
| 2017-04-03 | 65.809998 | 65.940002 | 65.190002 | 65.550003 | 20352800 | 65.550003 |
| 2017-04-04 | 65.389999 | 65.809998 | 65.279999 | 65.730003 | 12981200 | 65.730003 |
| 2017-04-05 | 66.300003 | 66.349998 | 65.440002 | 65.559998 | 21381100 | 65.559998 |
| 2017-04-06 | 65.599998 | 66.059998 | 65.480003 | 65.730003 | 18070500 | 65.730003 |
Transforming Data
The data from the api do not have available values for the dates the market is closed. This will cause errors on the processing of the data. The ffill method will be userd to add those missing data with the value of the previous available date.
On this section I will compile the train and test data. This will be two sliced datasets out of the original time series. During this process I am also filtering out the columns I don’t need keeping just the Close price of the stock, which will be the values up the model will be build.
original_data = data.fillna(method='ffill')
ran = pd.date_range(start_date, end_date, freq = 'D')
original_data = pd.Series(original_data['Close'], index = ran)
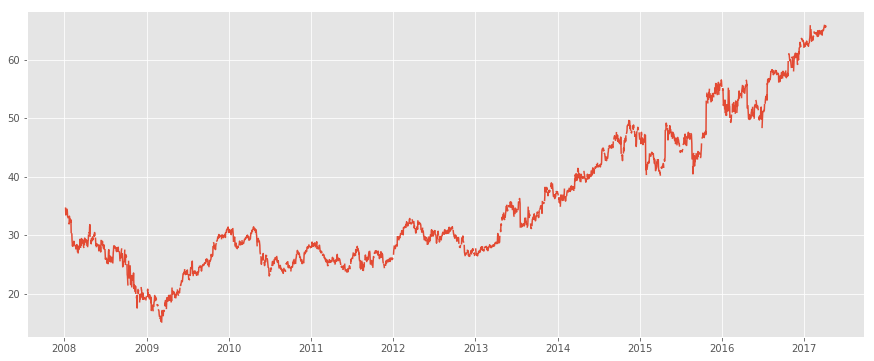
plt.plot(original_data)
plt.show()
original_data = original_data.fillna(method='ffill')
split = len(original_data) - predict_days
train_data, prediction_data = original_data[0:split], original_data[split:]
train_data.tail(5)
2017-03-31 65.860001
2017-04-01 65.860001
2017-04-02 65.860001
2017-04-03 65.550003
2017-04-04 65.730003
Freq: D, Name: Close, dtype: float64
Diagnostics
Stationarity
For the model to be build we need to check the series for stationarity. The code below renders the autocorrelation and partial autocorrelation charts.
# rendering such a large time series is compute intensive so I'm breaking it up
didive_large_series_by = 10
fig, axes = plt.subplots(1, 2, figsize=(15,4))
fig = plot_acf(train_data,
lags = abs(train_data.shape[0]/didive_large_series_by),
ax=axes[0])
fig = plot_pacf(train_data,
lags = abs(train_data.shape[0]/didive_large_series_by),
ax=axes[1])
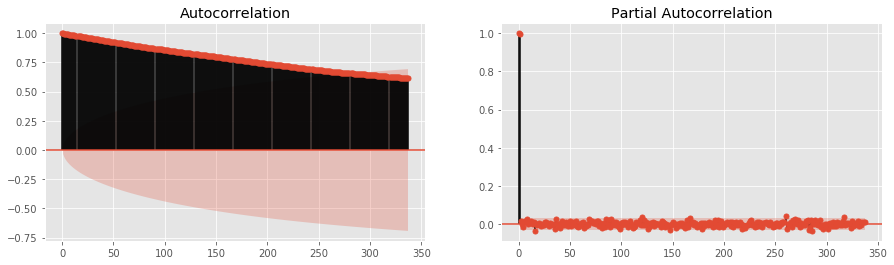
The autocorrelation plot indicates that the time series are not stationary because the values are not reduced at a significant pace. The partial autocorrelation graph above indicates that the value on lag 1 is the only one which is significantly different from 0, so a model AR(1) should be enough.
symbol_diff = train_data - train_data.shift()
symbol_diff = symbol_diff.dropna()
symbol_diff.head(4)
2008-01-05 0.00
2008-01-06 0.00
2008-01-07 0.23
2008-01-08 -1.16
Freq: D, Name: Close, dtype: float64
plt.plot(symbol_diff)
plt.title('First Difference Time Series Plot')
plt.show()
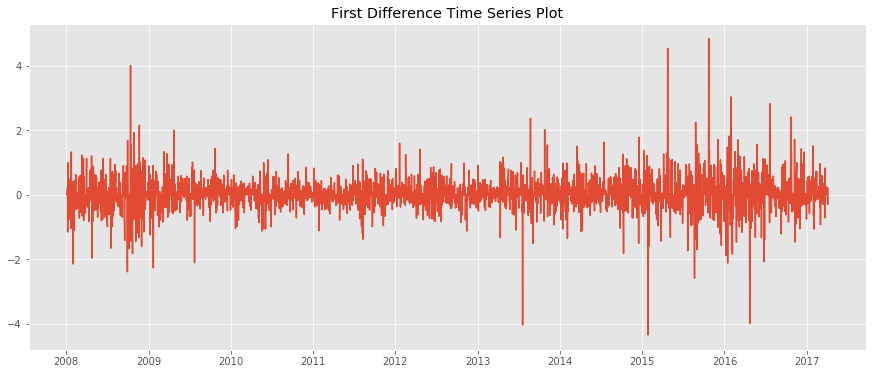
These are the manual steps that can be followed in order to check a signal for stationarity and transform it to be usable for the ARMA models. Since this process is quite manual and there needs to be way to let the program decide whether a time series is stationary or not I am going to use the Ad-fuller test on the next step.
Ad-fuller test
The process above showed how you can check for stationarity and manually transform the time series. With the ad-fuller test we have a process to check for stationarity which, computetionally, is more convenient.
from collections import namedtuple
ADF = namedtuple('ADF', 'adf pvalue usedlag nobs critical icbest')
stationarity_results = ADF(*smt.adfuller(train_data))._asdict()
significance_level = 0.01
if (stationarity_results['pvalue'] > significance_level):
message = 'For p-value={:0.4f}, the time series are probably non-stationary'
print(message.format(stationarity_results['pvalue']))
else:
message = 'For p-value={:0.4f}, the time series are probably stationary'
print(message.format(stationarity_results['pvalue']))
print(stationarity_results['critical'])
For p-value=0.9911, the time series are probably non-stationary
{'5%': -2.862399816394662, '1%': -3.4322959703836289, '10%': -2.5672276970758641}
Building the model
- I will pick an ARIMA(1,1,1) because of non-stationary time series. I’ve noticed that you cannot use any kind of combination on ARIMA(p, d, q). For example the (1,2,1) fails to converge while the (3,2,1) works better and has smaller error rates. An explanation of ARIMA(1,1,1) could be the following. We need a model which will try to explain data points with their mean, variance and autocorrelation not being constant, by fixing them with differenciation and exponential smoothing. Practically the AR(1) fixes the positive autocorrelation while and MA(1) fixes the negative autocorrelation. Autocorrelation appears a lot in this context. There are many available explanations on what autocorrelation is. Practically when you analyze time series you don’t want the attribute of a specifit data point to affect the attributes of another data point in the future. For example the fact that this months sales are low, should not affect the sales of the next month. You don’t want your data points to be influenced by their own older values.
- p and q also affect the coefficients of the output. The Nth order creates N coefficients.
order = (1, 0, 1) # if the series are stationary, there is no need for an integrated order
if stationarity_results['pvalue'] > 0.01:
order = (1, 1, 1)
mod = ARIMA(train_data, order = order, freq = 'D')
results = mod.fit()
print(results.summary())
print('DW test is {}'.format(sm.stats.durbin_watson(results.resid.values)))
ARIMA Model Results
==============================================================================
Dep. Variable: D.Close No. Observations: 3378
Model: ARIMA(1, 1, 1) Log Likelihood -2289.348
Method: css-mle S.D. of innovations 0.477
Date: Thu, 04 May 2017 AIC 4586.697
Time: 16:21:40 BIC 4611.197
Sample: 01-05-2008 HQIC 4595.456
- 04-04-2017
=================================================================================
coef std err z P>|z| [0.025 0.975]
---------------------------------------------------------------------------------
const 0.0093 0.007 1.405 0.160 -0.004 0.022
ar.L1.D.Close 0.8490 0.059 14.483 0.000 0.734 0.964
ma.L1.D.Close -0.8781 0.053 -16.637 0.000 -0.982 -0.775
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.1779 +0.0000j 1.1779 0.0000
MA.1 1.1388 +0.0000j 1.1388 0.0000
-----------------------------------------------------------------------------
DW test is 2.01217370914
The first thing we need to mention on the summary above is that the true parameters(coef) exist in the 95% confidence interval. The durbin watson test is close to 2 which indicates the lack of autocorrelation.
prediction = results.predict(prediction_data.index[0],
prediction_data.index[-1],
typ='levels')
prediction.tail(predict_days)
2017-04-05 65.730335
2017-04-06 65.732022
Freq: D, dtype: float64
fig, ax = plt.subplots(figsize=(12, 8))
plt.title("Actual Close price Vs. Forecasted Values")
ax = original_data.ix[len(original_data)-predict_days*10:].plot(ax=ax)
fig = results.plot_predict(prediction_data.index[0],
prediction_data.index[-1],
dynamic=True,
ax=ax,
plot_insample=False)
legend = ax.legend(loc='upper left')
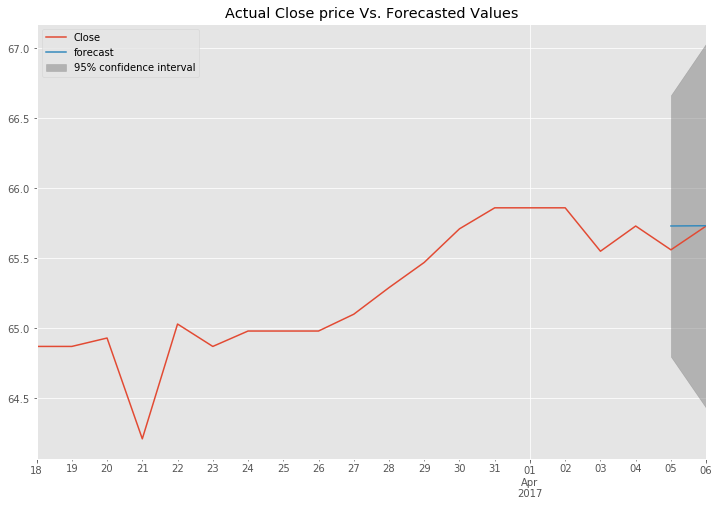
The graph above shows the predicted values as well and a confidence interval indicating that we can be 95% sure that the price will be between 64.5 and 67. This graph and this confidence interval is rendered for the MSFT symbol using the date range from 2008-01-04 to 2017-04-04 as train data and predicting the dates 2017-04-05 and 2017-04-06.
On time series the perfomance of the model is quantified by the mean forecast error which I am calculating on the next step.
mean_forecast_error = original_data.ix[-predict_days:].sub(prediction).mean()
print('Mean forecast error is {:.2%}'.format(abs(mean_forecast_error)))
Mean forecast error is 8.62%
Benchmarking
I’m going to check the performance of my model towards a naive prediction. Naive prediction is simply the last day’s value as a forecast for the next day. In python you can simulate this by shifting the prices of the original data by one and compare them with the predicted values as bellow.
naive_prediction = original_data.tail(predict_days+1).shift(1).tail(predict_days)
percentage_change = abs((prediction/naive_prediction-1) *100)
df = pd.concat([naive_prediction, prediction, percentage_change], axis=1)
df.columns = ['Original', 'Predicted', '% Prediction Diff']
df
| Original | Predicted | % Prediction Diff | |
|---|---|---|---|
| 2017-04-05 | 65.730003 | 65.730335 | 0.000505 |
| 2017-04-06 | 65.559998 | 65.732022 | 0.262391 |
Compine information
Lets try to check the mean errors for a range of prediction days. To do this I use the model I’ve created above and with every iteration I will be calculating again the train and the test data based on the number of the given prediction days.
mean_errors = []
for number_of_days in range(1, 20):
split = len(original_data) - number_of_days
train_data, prediction_data = original_data[0:split], original_data[split:]
mod = ARIMA(train_data, order = (1, 1, 1), freq = 'D')
results = mod.fit(disp=0)
prediction = results.predict(prediction_data.index[0],
prediction_data.index[-1],
typ='levels')
original_data_sample = original_data.ix[-number_of_days:]
mean_errors.append(abs(original_data_sample.sub(prediction).mean()))
plt.plot(mean_errors)
plt.show()
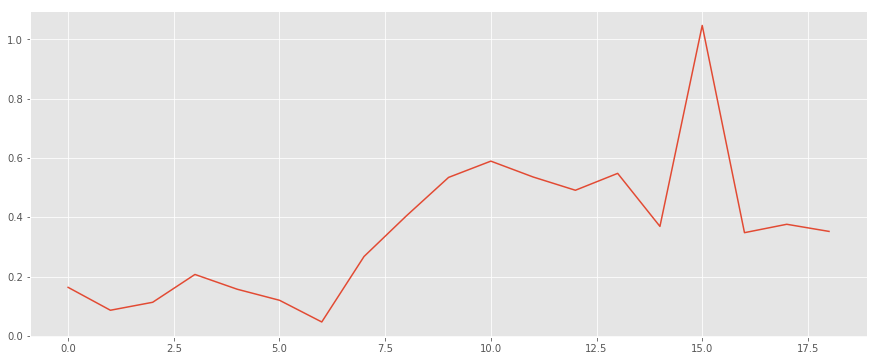
As we notice there is a good prediction rate up to the first 6 days with a mean error of around 20%. After that the error explodes and it even exceeds the 100% mark on the 15 days.
One more interesting experiment is to run the same model for a number of different stock symbols and check how it performs on different signals. I will focus on similar industry symbols.
symbols = ['MSFT', 'NVDA', 'CSCO', 'ORCL', 'SYMC', 'INTC', 'EBAY', 'YHOO']
mean_errors = []
for symbol in symbols: # this can be improved with multiprocessing or async calls
data = web.DataReader(symbol, source, start, end)
original_data = data.fillna(method='ffill')
ran = pd.date_range(start_date, end_date, freq = 'D')
original_data = pd.Series(original_data['Close'], index = ran)
original_data = original_data.fillna(method='ffill')
split = len(original_data) - predict_days
train_data, prediction_data = original_data[0:split], original_data[split:]
mod = ARIMA(train_data, order = (1, 1, 1), freq = 'D')
results = mod.fit(disp=0)
prediction = results.predict(prediction_data.index[0],
prediction_data.index[-1],
typ='levels')
original_data_sample = original_data.ix[-number_of_days:]
mean_errors.append(abs(original_data_sample.sub(prediction).mean()))
N = len(mean_errors)
x = range(N)
width = 1/1.5
plt.bar(x, mean_errors, width, color="blue")
plt.xticks(x, symbols)
plt.show()
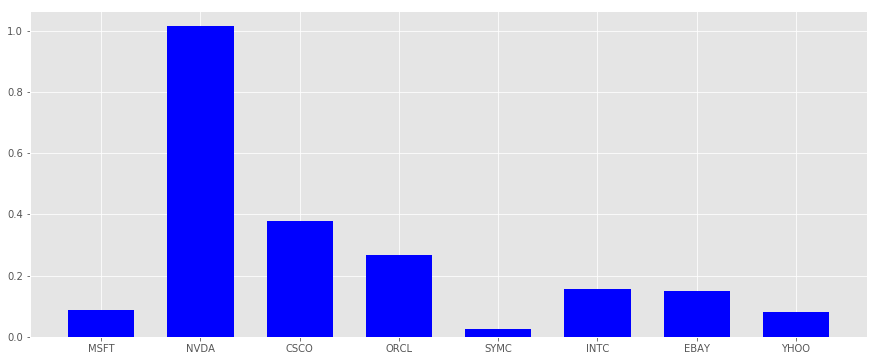
The experiment above indicates that for the most symbols there was a very good prediction mean error of less than 20%. The model failed to predict NVIDIA complitelly and was less performant for CISCO and ORACLE.
Conclusions
With this exercise I have tested the predictive capabilities of the ARIMA group of models. I have also investigated the performance of my models towards multiple input days and the performance on multiple input symbols for the same date range.
ARIMA proved to be quite performant in most occasions. The mean forecast error for predicting two days for the microsoft stock price proved to be just 0.26% different than the naive benchmark for the same days.
There are some cases where the model did not perform well. Henry and Mizon wrote an interesting paper on unpredictability of the econometric modeling and I quote “Unpredictability arises from intrinsic stochastic variation, unexpected instances of outliers, and unanticipated extrinsic shifts of distributions.”. A simple explanation of this could summarized as follows. An econometric model can fail because of internal unknown processes, unexpected failures which affect the train data and changes on external distributions such as the market, economy or governmental policy.
Another interesting project, would be to expand this time series analysis and use multiple models for the same prediction period and pick the one which works the best for the specific underlying target. In modern computing systems this process can be spanned across multiple machines and predict multiple combinations of symbols and date ranges in parallel.
Detailed instructions on how to run this notebook
- Probably the easiest solution for non python experts is the anaconda distribution https://www.continuum.io/downloads. It contains a great set of tool for scientific computing out of the box. The full list of available modules is here https://docs.continuum.io/anaconda/pkg-docs. If you will go with this solution jump to step 7.
- Check your python distribution with
python -V. It needs to be at least 2.7 and have the pip package manager installed. Check the pip version withpip -VIf case you do not have pip installed check out the instructions here https://pip.pypa.io/en/stable/installing/ - Install virtualenv https://virtualenv.pypa.io/en/stable/installation/. Virtualenv is a tool which allows you to have separate python groups of modules in order to keep the global Python installation clean and avoid module versions conflicts.
- Create a virtual env with the command
mkvirtualenv arimamodeland verify you are using this environment with the commandworkon arimamodel - Update pip with
pip install -U pip - Install all the needed modules with
pip install numpy==1.12.1 statsmodels==0.8.0 matplotlib==2.0.0 jupyter==1.0.0 pandas-datareader==0.3.0.post0 - Navigate to the directory where this .ipynb file is and run the command
jupyter notebook. You should be redirected to the browser and you should be able to select this specific notebook. - Make sure you execute each cell to make all the statements available to the code flow. You can run each cell either by selecting it and click on Cell->Run Cell from the top menu or by selecting it and hit the keys Crtl+Enter.
Works cited
Ayodele A. Adebiyi, Aderemi O. Adewumi, Charles K. Ayo, “Stock Price Prediction Using the ARIMA Model”, UKSim-AMSS 16th International Conference on Computer Modelling and Simulation 2014
David F. Hendry, Grayham E. Mizon, “Unpredictability in Economic Analysis, Econometric Modeling and Forecasting” University of Oxford 2013
Michael Wagner, “Forecasting Daily Demand in Cash Supply Chains”, American Journal of Economics and Business Administration 2 (4): 377-383, 2010 ISSN 1945-5488, 2010
Javier Contreras, Rosario Espínola, Francisco J. Nogales, Antonio J. Conejo, “ARIMA Models to Predict Next-Day Electricity Prices”, IEEE Transactions on power systems, vol 18, no 3, Aug. 2003
IMPORTANT NOTE
This notebook exists for informational purposes only. This analysis does not contain quality predictions. A production system has to cross-validate the findings and predict a greater amount of assets in order to create valid trading strategies. There are no guarantees for accuracy or completeness and this guide can change at any time.